Dieses Tutorial basiert grundsätzlich auf einer Hausarbeit im Modul “Datenanalyse & -auswertung”, welches ich im vergangenen Semester im Rahmen meines Studiums “Information Science” an der HU Berlin belegt habe. Auch wenn es online bereits zahlreiche vergleichbare Ressourcen gibt, habe ich mich schlussendlich doch für eine Veröffentlichung entschieden, nicht zuletzt da mir selbst in der Vergangenheit (u.a. auch für die genannte Hausarbeit) entsprechende Beispiele und Erklärungen schon häufig weitergeholfen haben.
Inhalt
Einleitung
Wir befinden uns in einer Zeit, in der nicht nur Verschwörungstheorien vom “Informationskrieg” handeln, sondern auch die obersten Ränge von Politik, Wissenschaft und Gesellschaft die Gefahren rund um Desinformation und “Fake News” erkennen und Lösungsansätze entwickeln – eine Thematik also, die gerade für die Informationswissenschaft von heute eine wesentliche Rolle spielt. Diese hochaktuelle Debatte soll u.a. Gegenstand des vorliegenden Tutorials sein und als Motivator dient folgender Tweet Donald Trumps vom 11. Dezember 2014:
Policy towards our enemies: Hit them hard, hit them fast, hit them often & then tell them it was because they are the enemy!
— Donald J. Trump (@realDonaldTrump) December 11, 2014
Dass Trump später immer wieder die primär nicht-konservativen Nachrichtenmedien als Feind der amerikanischen Bevölkerung bezeichnet, wird unter anderem in dem Artikel “Defining the Enemy: How Donald Trump Frames the News Media” [Meeks 2019] herausgestellt. Allgemein sind Nachrichten und Medien ein vergleichsweise häufig adressiertes Thema in Tweets Trumps [Meeks 2019, S. 17] [Wang et al. 2016, S. 721], dessen Analyse relevante und neuartige Ergebnisse hervorbringen kann. Unser Mediensystem vollzieht aktuell eine Transformation von kontrollierten Top-Down-Prozessen mit journalistischen Gatekeepern hin zu einem stärker dezentralisierten “hybrid media system” (der Begriff geht auf Chadwicks “The Hybrid Media System: Politics and Power” zurück), in welchem digitale wie gedruckte Medien koexistieren. Die sozialen Medien erleichtern hierbei nicht nur die direkte Ansprache der Zielgruppe sowie die Dissemination von Information an ein potentiell nahezu unbegrenztes Publikum, sie unterstützen vor allem die “Entwicklung populistischer, ethnonationaler und Anti-Establishment Communities” [frei übersetzt nach Wells et al. 2020, S. 663] in besonderem Maße.
Weiterhin verwendet Trump sogenanntes “framing” als Überzeugungsstrategie: “the presence or absence of certain keywords, stock phrases, stereotyped images, sources of information, and sentences that provide thematically reinforcing clusters of facts or judgments” [Entman 1993, S. 52, zitiert nach Meeks (2019), S. 3]. Twitters Retweet-Funktion unterstützt das Framing zusätzlich:
“Twitter gives users an easy way to repeat Trump’s frames verbatim via the retweet function. […] Twitter’s ‘shareability’ enables Trump’s frames and influence to spread outward across peer networks, adding momentum to his framing.”
Meeks 2019, S. 7.
Insofern liegt die Verantwortung für Inhalte nicht mehr ausschließlich beim Informationsproduzenten, sondern auch bei der Plattform, welche die vielfältigen Funktionalitäten zur Vernetzung und Informationsdiffusion zwischen Akteuren ermöglicht. ↑
Vorbereitung
In diesem Tutorial wird die Programmiersprache Python verwendet. Die Codebeispiele stammen aus einem Jupyter Notebook, welches über Github abgerufen werden kann.
Für die Analyse der Twitterdaten wurde eine ganze Reihe an Python-Bibliotheken verwendet, u.a. zur Formatierung und Verarbeitung der Daten sowie für Statistiken und Visualisierungen. In einem ersten Schritt müssen diese Bibliotheken mit einem package manager wie pip oder Conda installiert werden, bevor sie importiert werden können.
#import all necessary modules
# general
import json
import pandas as pd
#numbers and time
import numpy as np
from collections import Counter
from datetime import datetime
# text
import re #regular expressions
import preprocessor as p #from tweet-preprocessor library, see https://pypi.org/project/tweet-preprocessor/
from textblob import TextBlob #text processing library, here used to extract sentiment, see also https://textblob.readthedocs.io/en/dev/
from nltk import ngrams
#stats
from scipy import stats
import researchpy as rp
# visualizations
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
from plotly.colors import n_colors
import seaborn as sn
Der hier verwendete Datensatz wurde über das Trump Twitter Archive abgerufen. Diese Sammlung enthält bereits jetzt über 50.000 Tweets des persönlichen Twitter-Accounts Donald Trumps @realDonaldTrump und eine Weiterverwendung dieser Daten empfiehlt sich, da im Gegensatz zur Twitter API (siehe hierzu Tweet Availability) auch die Mehrheit der gelöschten Tweets zugänglich gemacht werden (interessant ist in diesem Zusammenhang auch der Blogpost Tweets and Deletes). Der Datensatz wurde am 04.08.2020 über eine Suche nach folgenden Begriffen (mit der Option “exact word search”, Groß-/Kleinschreibung ausgeschlossen) generiert:
- news
- media
- press
- fact
- facts
- information
- cnn
- nbc
- abc
- cbs
- nytimes
- newyorktimes
- ny times
- fox
Preprocessing
Im Anschluss geht es an die Vorbereitung und Bereinigung der Daten, wobei zusätzliche Spalten aus den Inhalten der bisherigen Daten erzeugt und auch durch weiterführende Analysen neue Spalten hinzufügt werden können. Als Erstes müssen jedoch die Daten, welche als JSON-Datei vorliegen, geladen und in einen Pandas Dataframe konvertiert werden. Dies erleichtert spätere Analysen.
#read json file
with open("dataset_media.json", 'r',encoding="utf8") as f:
datastore = json.load(f)
# convert json to dataframe
df = pd.json_normalize(datastore)
df
| source | text | created_at | retweet_count | favorite_count | is_retweet | id_str | |
|---|---|---|---|---|---|---|---|
| 0 | Twitter for iPhone | RT @WhiteHouse: LIVE: President @realDonaldTru… | Mon Aug 03 21:36:46 +0000 2020 | 4971 | 0 | True | 1290401249251270663 |
| 1 | Twitter for iPhone | My visits last week to Texas and Florida had m… | Mon Aug 03 15:27:41 +0000 2020 | 24241 | 111167 | False | 1290308363872538624 |
| 2 | Twitter for iPhone | RT @realDonaldTrump: FAKE NEWS IS THE ENEMY OF… | Mon Aug 03 13:53:10 +0000 2020 | 78121 | 0 | True | 1290284578578419712 |
| 3 | Twitter for iPhone | Wow! Really bad TV Ratings for Morning Joe (@J… | Mon Aug 03 12:57:35 +0000 2020 | 15131 | 72174 | False | 1290270589945430016 |
| 4 | Twitter for iPhone | My visits last week to Texas and Frorida had m… | Mon Aug 03 12:46:02 +0000 2020 | 12976 | 59426 | False | 1290267685117460481 |
| … | … | … | … | … | … | … | … |
| 4238 | Twitter Web Client | Donald Trump appearing today on CNN Internatio… | Wed Feb 10 15:17:56 +0000 2010 | 7 | 1 | False | 8905123688 |
| 4239 | Twitter Web Client | Celebrity Apprentice returns to NBC, Sunday, 3… | Tue Jan 12 18:05:08 +0000 2010 | 20 | 3 | False | 7677152231 |
| 4240 | Twitter Web Client | Reminder: The Miss Universe competition will b… | Sun Aug 23 21:12:37 +0000 2009 | 1 | 4 | False | 3498743628 |
| 4241 | Twitter Web Client | Watch the Miss Universe competition LIVE from … | Fri Aug 21 14:32:45 +0000 2009 | 1 | 3 | False | 3450626731 |
| 4242 | Twitter Web Client | Read a great interview with Donald Trump that … | Wed May 20 22:29:47 +0000 2009 | 4 | 3 | False | 1864367186 |
Zusätzlich werden mit verschiedenen Methoden Retweets herausgefiltert, da diese für die Analyse nicht weiter relevant sind (Trumps eigene Äußerungen über Tweets sollen im Vordergrund stehen).
Ein letzter Vorverarbeitungsschritt betrifft das verwendete Zeitformat – für eine Analyse werden die Daten in das UTC-Format transformiert und einzelne Jahre in ähnlicher Weise daraus extrahiert.
# transform col "created_at" into recognizable UTC time values as dates/date type
# see also https://stackoverflow.com/questions/7703865/going-from-twitter-date-to-python-datetime-date
# define function, using datetime module
def change_dates(dataframe, index):
for tweet in dataframe:
dataframe.iloc[index] = datetime.strftime(datetime.strptime(dataframe.iloc[index],'%a %b %d %H:%M:%S +0000 %Y'), '%Y-%m-%d %H:%M:%S')
index += 1
# call function for col "created_at"
change_dates(df_media["created_at"], 0)
Textverarbeitung
Mittels Regular Expressions werden außerdem Hashtags und Mentions identifiziert, welche für eine Auswertung in einer separaten Spalte gespeichert werden.
# search for hashtags and mentions, put them in own columns
#hashtags
hashtag_re = re.compile("#(\w+)")
df_media['hashtags'] = np.where(df_media.text.str.contains(hashtag_re), df_media.text.str.findall(hashtag_re), "")
#mentions
mention_re = re.compile("@(\w+)")
df_media['mentions'] = np.where(df_media.text.str.contains(mention_re), df_media.text.str.findall(mention_re), "")
Weiter unten soll für die Tweets eine simplifizierte Sentimentanalyse durchgeführt werden. Hierzu werden zunächst die Tweets mit der preprocessor-Library in einem weiteren (Text-)Vorverarbeitungsschritt von Informationen wie Hashtags, Mentions oder URLs bereinigt, sodass diese die Bewertung des Sentimentwerts nicht beeinflussen.
df_media['cleaned_text'] = df_media["text"] #copy col text to cleaned_text
p.set_options(p.OPT.HASHTAG, p.OPT.URL, p.OPT.EMOJI, p.OPT.MENTION) #set options for cleaning: clean text from hashtags, mentions, urls and emojis
# define function clean_text() which will append the predefined options to each row
def clean_text(dataframe, index):
for row in dataframe:
dataframe.iloc[index] = p.clean(dataframe.iloc[index])
index += 1
# call clean_text() for col "cleaned_text"
clean_text(df_media["cleaned_text"], 0)Für die Sentimentanalyse wird in folgendem Beispiel die Bibliothek Textblob verwendet.
#create df containing polarity values for each tweet in the dataset
tweet_text = [] # create an empty list
for index, col in df_media.iterrows():
tweet_text.append(df_media.cleaned_text[index]) # append each tweet to it
sentiment_objects = [TextBlob(tweet) for tweet in tweet_text] # apply textblob for each tweet in tweet_text
sentiment_values = [[tweet.sentiment.polarity, str(tweet)] for tweet in sentiment_objects] # create a new list of polarity values and tweet text
sentiment_df = pd.DataFrame(sentiment_values, columns=["polarity", "tweet"]) # transform list into dataframe and sort the values accordingly
sentiment_df.sort_values("polarity", ascending=True)Wir erhalten eine Liste aller Tweets, sortiert nach Polaritätswerten:
| polarity | tweet | |
|---|---|---|
| 1756 | -1.0 | find the leakers within the FBI itself. Classi… |
| 2119 | -1.0 | FMR PRES of Mexico, Vicente Fox horribly used … |
| 2620 | -1.0 | If you look at the horrible picture on the fro… |
| 2908 | -1.0 | The media is pathetic. Our embassies are savag… |
| 1316 | -1.0 | Some people HATE the fact that I got along wel… |
| … | … | … |
| 472 | 1.0 | Triggered, a great book by my son, Don. Now nu… |
| 972 | 1.0 | Great news! |
| 969 | 1.0 | Finally great news at the Border! |
| 1501 | 1.0 | Great news, as a result of our TAX CUTS & … |
| 696 | 1.0 | Jesse & Emma, Great News. Congratulations!… |
Um die Polarität mit anderen Werten aus unserem Dataframe vergleichen/analysieren zu können, muss dafür eine zusätzliche Spalte hinzugefügt werden.
df_media = df_media.reset_index(drop=True)
df_media['sentiment_values'] = pd.Series(sentiment_df['polarity'])Alternativ können die reinen Polaritätswerte auch in Beschreibungen umgewandelt werden, es müssen lediglich entsprechende Grenzwerte gefunden werden (in diesem Codebeispiel: negativ<= -0.33 < neutral <= 0.33 < positiv).
df_media["sentiment"] = "" # new col
# define function to devide sentiment_values into sentiments ("negative","neutral","positive")
def get_sentiment(dataframe, index):
for tweet in dataframe:
if df_media.sentiment_values.iloc[index] <= -0.33:
df_media.sentiment.iloc[index] = "negative"
elif (df_media.sentiment_values.iloc[index] > -0.33) & (df_media.sentiment_values.iloc[index] <=0.33):
df_media.sentiment.iloc[index] = "neutral"
else:
df_media.sentiment.iloc[index] = "positive"
index += 1
# apply get_sentiment()
get_sentiment(df_media["sentiment_values"], 0)Datenanalyse
Deskriptive Analyse
Mit der Funktion pandas.Dataframe.describe() können erste Kennzahlen für Minimum, Maximum, Mittelwert, Standardabweichung und Quantile generiert werden. Desweiteren kann die Verteilung der Ausprägungen beispielsweise mittels Histogramm oder Boxplot visualisiert werden.


Die oben gezeigten Histogramme deuten bereits eine rechtsschiefe Verteilung für Retweets und Likes im Datensatz an. Für die im Nachhinein berechneten Polaritätswerte scheint annäherungsweise eine Normalverteilung vorzuliegen. Nachfolgend wird beispielhaft gezeigt, wie die Erstellung eines solchen Histogramms mit matplotlib.pyplot.hist() aussehen könnte.
# plot data
fig, ax = plt.subplots()
ax.hist(df_media.retweet_count, color = "blue", alpha=0.5, bins=20)
ax.hist(df_media.favorite_count, color = "aquamarine", alpha=0.5, bins=60)
# add labels, title, legend
ax.set_ylabel('Häufigkeit')
ax.set_xlabel('Anzahl der Retweets/Likes')
ax.set_title(r'Verteilungen retweet_count/favorite_count')
ax.legend()
#show plot
plt.show()

Boxplots sind eine weitere Möglichkeit zur Visualisierung der Verteilung numerischer Variablen. Die Abbildung zeigt Beispiele für die gleichen drei Variablen, erstellt mit plotly.graph_objects.Box.
# boxplot favorite_count
data = df_media.favorite_count
# plot
fig = go.Figure()
fig.add_trace(go.Box(y=data, name="favorite_count", marker_color="lightseagreen", boxpoints="all", jitter=0.6,
pointpos=-2, marker=dict(opacity=0.5), marker_size=5, width=40))
# update layout
fig.update_layout(width=400, height=800, font=dict(color="black"), plot_bgcolor="white", xaxis = dict(gridcolor = "#ededed", gridwidth=3), yaxis=dict(gridcolor = "#ededed", gridwidth=3))
#show plot
fig.show()Die bisherigen Visualisierungen sind auf metrische Variablen ausgerichtet, für nominal bzw. ordinal skalierte Daten muss ggf. auf alternative, simplere Methoden zurückgegriffen werden.

Dieses Sunburst Chart (Spezialfall eines Pie Charts) beinhaltet die in den Tweets des Datensatzes enthaltenen Hashtags, welche mit ein wenig zusätzlichem qualitativen Aufwand in allgemeinere Kategorien ("medien", "medienkritik", "politisches", "show", "sonstiges", "wahlkampf") zusammengefasst wurden. Neben den zu erwartenden Hashtags zu Medien ("medien", "medienkritik", "show") sind insbesondere viele Hashtags enthalten, die der Kategorie "wahlkampf" zugeordnet wurden (u.a. #maga, #trump2016).
# plot
fig = px.sunburst(hashtags_df, path=["category", "hashtag"], values='frequency', color="frequency", color_continuous_scale=[[0,"white"],[1.0, "blue"]])
# update layout
fig.update_layout(width=900, height=900, uniformtext=dict(minsize=13, mode='hide'),coloraxis_showscale=False) # labels of hashtags with frequency=1 are not shown (by "minsize=13, mode='hide'")
# show plot
fig.show()

Bei dem Bar Chart handelt es sich um eine Darstellung der 10 am häufigsten erwähnten Accounts (mentions). Primär besteht diese aus Accounts der Nachrichtensender, die bereits als Begriffe für die Zusammenstellung des Datensatzes verwendet wurden (@cnn, @nytimes, @foxnews, @nbc, @foxandfriends, @abc, @nbcnews sowie zusätzlich die @washingtonpost).
Hierfür werden (bei den Hashtags ist dieser Schritt ähnlich) zuerst die Mentions in eine Liste überführt, dann die einzelnen Häufigkeiten dieser Mentions ausgezählt und die Ergebnisse in einem neuem Dataframe gespeichert sowie nach der Häufigkeit sortiert.
mentions = [] # create empty list
# iterate through all mentions and append them to list
for index, col in df_media.iterrows():
mentions.append(df_media.mentions[index])
# change nested list to flat list
# see https://stackoverflow.com/questions/952914/how-to-make-a-flat-list-out-of-list-of-lists
flat_list = []
for sublist in mentions:
for item in sublist:
item = item.lower()
flat_list.append(item)
# create dict for mentions by counting occurences of each item, then transform mentions and frequencies into a dataframe (mentions_df)
mentions_dict = Counter(flat_list)
mentions_df = pd.DataFrame(list(mentions_dict.items()),columns = ["mention", "frequency"])
# sort mentions in descending order
mentions_df = mentions_df.sort_values(by="frequency", ascending=False).reset_index(drop=True)
Anschließend können die ersten zehn Mentions entsprechend visualisiert werden:
data = mentions_df.iloc[:11]
# plot
fig = px.bar(data, x="mention", y="frequency")
fig.update_traces(marker_color='lightseagreen', opacity=.6, texttemplate='%{y}', textposition='outside')
# update layout
fig.update_layout(width=800, height=500, font=dict(size=12, color="black"), plot_bgcolor="white", xaxis = dict(gridcolor = "#ededed", gridwidth=1), yaxis=dict(gridcolor = "#ededed", gridwidth=1))
# show plot
fig.show()
Relationen zwischen Variablen
Zusammenhänge zwischen Variablen lassen sich unter anderem gut in Form von sogenannten Scatterplots (Streudiagrammen) darstellen. Für die Visualisierungen wurde weiterhin die Bibliothek Plotly verwendet. Die Berechnung der statistischen Werte wurde mit der Python-Bibliothek researchpy durchgeführt. Diese macht übersichtliche statistische Zusammenfassungen verfügbar und baut u.a. auf statistische Funktionen von scipy.stats auf.

Die Abbildung zeigt die Variablen source (verwendetes Endgerät/Applikation) und created_at (Veröffentlichungszeitpunkt des Tweets) in Form eines solchen Scatterplots. Farblich werden hier wie auch in den nachfolgenden Streudiagrammen die Polaritätswerte der Tweets repräsentiert. Die drei meistgenutzten Kanäle (Twitter for Android, Twitter Web Client und Twitter for iPhone) unterscheiden sich - wie in dieser Darstellung deutlich wird - vor allem nach ihrem zeitlichen Einsatz. Diese zeitliche Unterteilung nach verwendeten "tweet sources" deckt sich u.a. mit den Beobachtungen von [Clarke/Grieve 2019, S. 5f.] und deren deutlich umfangreicheren Daten.
df = df_media
# plot
fig = px.scatter(df, x="created_at", y="source",color="sentiment_values", color_continuous_scale=["orangered","greenyellow","blue"], opacity=.5)
# update layout
fig.update_layout(font=dict(size=12, color="black"), plot_bgcolor="white", xaxis = dict(gridcolor = "#ededed", gridwidth=2), yaxis=dict(gridcolor = "#ededed", gridwidth=2), width=1200)
# show plot
fig.show()
Da das Merkmal source nominalskaliert ist, wird der Chi-Quadrat-Test angewendet. Hierbei sollte darauf geachtet werden, dass die erwarteten Häufigkeiten jeweils über 5 liegen, in jedem Fall jedoch "der Anteil der erwarteten Häufigkeiten, die kleiner als 5 sind, 20% nicht überschreite[n]" [Bortz 2005, S. 177] darf. Im vorliegenden Fall wurde der Datensatz um die selten auftretenden Merkmalsausprägungen (alle "sources" bis auf Twitter Web Client, Twitter for Android und Twitter for iPhone; das Jahr 2009) reduziert, um diese Voraussetzung zu erfüllen.
| Datensatz | Pearson Chi-Quadrat | p-Wert | Cramers V |
|---|---|---|---|
| ursprünglich (df=143.0) | 4984.11 | 0.00 | 0.38 |
| angepasst (df=20.0) | 3236.34 | 0.00 | 0.73 |
Für die angepassten Daten (df=20) zeichnet sich ein starker Effekt (V = 0.73) ab, wodurch davon ausgegangen werden kann, dass zumindest zwischen den am häufigsten verwendeten Endgeräten und den zeitliche Abständen in Jahren ein gewisser Zusammenhang im Datensatz gefunden werden kann. Der Chi-Quadrat-Test wurde mithilfe der Funktion crosstab() durchgeführt.
crosstab, res, expected = rp.crosstab(df_media.source, df_media.year,prop="cell",test="chi-square",correction=True, cramer_correction=True, expected_freqs=True)

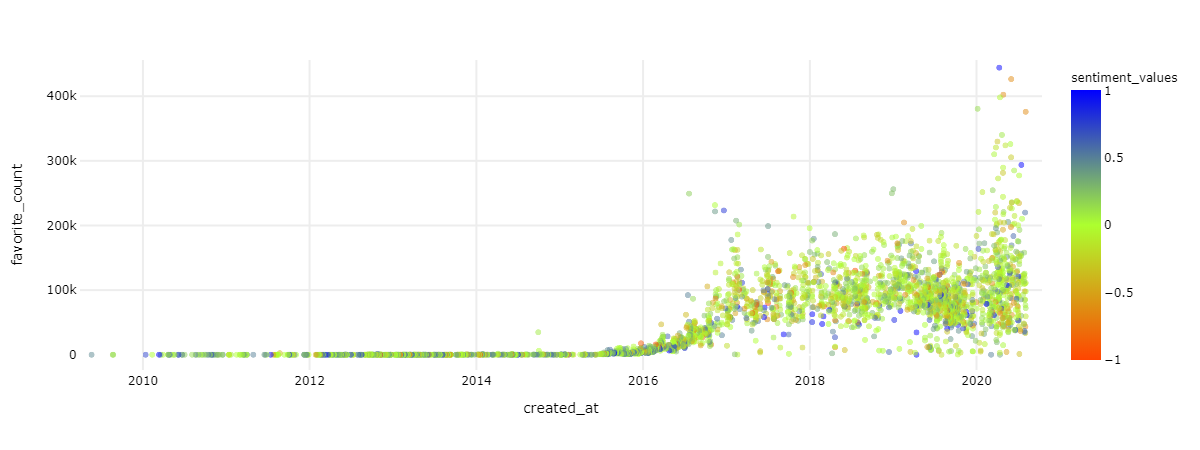
Die Scatterplots zeigen die Verteilung von Retweets bzw. Likes über die Zeit, wobei diese auf den ersten Blick sehr ähnlich ausfallen (auch wenn die Werte für favorite_count nach oben stärker gestreckt sind). Auffällig ist vor allem der starke Anstieg sowohl von Retweets als auch Likes für Tweets ab ca. 2016, also zum Zeitpunkt von Trumps Präsidentschaftskandidatur. Die folgende Tabelle fasst die Werte für die Korrelation mit parametrischen (Pearson) wie nicht-parametrischen Verfahren (Spearman, Kendall) für die Variablen retweet_count und year, favorite_count und year sowie favorite_count und retweet_count zusammen.
| Variablen | Methode | r-Wert | p-Wert |
|---|---|---|---|
| retweet_count x year | Pearson | 0.69 | 0.00 |
| Spearman | 0.75 | 0.00 | |
| Kendall | 0.59 | 0.00 | |
| favorite_count x year | Pearson | 0.71 | 0.00 |
| Spearman | 0.78 | 0.00 | |
| Kendall | 0.64 | 0.00 | |
| favorite_count x retweet_count | Pearson | 0.96 | 0.00 |
| Spearman | 0.98 | 0.00 | |
| Kendall | 0.88 | 0.00 |
Die Korrelationskoeffizienten können mit researchpy.corr_pair() berechnet werden:
rp.corr_pair(df_media[["retweet_count","favorite_count"]], method="kendall")
Die in der Tabelle festgehaltenen Werte für die Korrelation von retweet_count x year und favorite_count x year deuten auf einen starken und positiven linearen Zusammenhang hin. Die Variablen retweet_count und favorite_count mit ihren übermäßig hohen Werten für einen Zusammenhang könnten allerdings ein Anzeichen dafür sein, dass es sich um eine Scheinkorrelation ("spurious relationship"/"spurious correlation") handelt:
"A relationship between two variables that is caused by a statistical artifact or a factor, not included in the model, that is related to both variables."
Downey 2014, S. 143
Es könnte demnach eine Korrelation bestehen, die jedoch nicht kausal begründet werden kann. Vermutlich ist eine weitere, sogenannte konfundierende Variable ("Störvariable"), wie beispielsweise die über die Zeit ansteigende Followerzahl, ursächlich für eine ähnlich hohe Anzahl an Retweets wie Likes [vgl. Wang et al. 2016, S. 721]. ↑
Weiterführende Analyse
Die hier vorgestellte Auswahl an untersuchten Relationen zwischen Variablen lässt die Annahme zu, dass ein gewisser Zusammenhang zwischen verschiedenen Variablen und der zeitlichen Komponente, z.B. durch zunehmende Followerzahlen über die Zeit oder stategische Anpassungen im Laufe der Zeit, besteht. Die zeitliche Abhängigkeit linguististischer Veränderungen in Tweets Trumps wurde bereits von [Clarke/Grieve 2019] im Detail beleuchtet. Weiterführend könnte insofern beispielsweise analysiert werden, welche Inhalte Trump auf Twitter veröffentlicht und wie die Twitter-Community wiederum auf diese reagiert. Eine Forschungsfrage könnte demnach sein:
Was sind die häufigsten Aussagen (gemessen in N-Grammen) im Datensatz und wie sind diese über die Zeit verteilt?
Um diese Fragestellung zu adressieren, müssen zunächst alle Tweets in sogenannte N-Gramme, hier 5-Gramme (auch: Pentagramme) zerlegt werden. Dafür wurde das Modul ngrams des NLTK (Natural Language Toolkit) verwendet.
# copy df for this step, it gets messy
# df_media should stay as it is (deep=True)
df_ngrams = df_media.copy(deep=True)
#create a new column "ngrams"
df_ngrams["ngrams"] = ""
#def function to iterate through df and get all 5-grams within "cleaned_text"
def get_ngrams(dataframe, index):
for tweet in dataframe:
list_ngrams = []
n = 5
fivegrams = list(ngrams(df_ngrams.cleaned_text.iloc[index].split(), n))
dataframe.iloc[index] = fivegrams
index += 1
# call get_ngrams()
get_ngrams(df_ngrams["ngrams"], 0)
Um die N-Gramme tatsächlich auswerten zu können, müssen diese aus den verschachtelten Listen getrennt werden - ein Aufsplitten mit der pandas.DataFrame.explode()-Funktion löst das Problem jedoch nicht, da hier alle enthaltenen Listen aufgetrennt und anschließend nur noch einzelne Wörter enthalten sind. Eine Liste nur auf der obersten Ebene aufzusplitten gelingt über eine Nachnutzung der Funktion tidy_split() (siehe Github):
# call function tidy_split() and separate all ngrams per tweet from each other
df_grams = tidy_split(df_ngrams,"ngrams",sep="), (")
In der folgenden Tabelle sind die 10 häufigsten Pentagramme aus den Tweets einzusehen.
| Pentagramm | Anzahl |
|---|---|
| 'the', 'failing', 'new', 'york', 'times' | 30 |
| 'the', 'enemy', 'of', 'the', 'people!' | 25 |
| 'the', 'fake', 'news', 'media', 'is' | 19 |
| 'be', 'on', 'fox', '&', 'friends' | 15 |
| 'will', 'be', 'on', 'fox', '&' | 15 |
| 'i', 'will', 'be', 'having', 'a' | 13 |
| 'be', 'doing', 'fox', '&', 'friends' | 12 |
| 'is', 'the', 'enemy', 'of', 'the' | 12 |
| 'the', 'history', 'of', 'our', 'country.' | 11 |

Betrachtet man diese häufigsten Textfragmente im Datensatz nach ihrer zeitlichen Veröffentlichung, so wird deutlich, was aufgrund der vorausgegangen Untersuchungen schon erahnt werden konnte: spätestens ab dem Amtsantritt Trumps scheinen sich auch Sprache und Inhalte der Tweets zu ändern. Die Ergebnisse von Clarke/Grieve (2019) stimmen damit überein:
"All four dimensions showed clear temporal patterns and most major shifts in style align to a small number of indisputably important points in the Trump timeline, especially the 2011 Birther controversy, the 2012 election, his 2015 declaration, his 2016 Republican nomination, the 2016 election, and his 2017 inauguration, as well as the seasons of his television series The Apprentice."
Clarke/Grieve 2019, S. 19
Es sei zwar darauf hingewiesen, dass in der Abbildung nur ein kleiner Ausschnitt aller N-Gramme dargestellt wird (es wurden insgesamt 75756 N-Gramme aus dem Datensatz extrahiert). Dennoch kann vermutet werden, dass sich frühere Tweets eher mit Medien im Kontext des Unterhaltungsfernsehens (hier: Fox & Friends) auseinandersetzen, während insbesondere ab 2017 die Anzahl der distanzierenden und beschuldigenden Aussagen in Richtung Medien (Stichwörter wären "enemy", "fake news media", "failing") offensichtlich zunimmt. So macht Trump beispielsweise "die Fake News" oder "Fake News Medien" zum Feind ("the enemy of the people"):
CNN and others in the Fake News Business keep purposely and inaccurately reporting that I said the “Media is the Enemy of the People.” Wrong! I said that the “Fake News (Media) is the Enemy of the People,” a very big difference. When you give out false information - not good!
— Donald J. Trump (@realDonaldTrump) October 30, 2018
Natürlich sind die hier angeführten Beobachtungen allein nicht Beweis genug und es müssten weitere Analysen durchgeführt werden, um entsprechende Annahmen zu festigen. ↑
Ausblick
Abschließend sollen einige wesentliche Erkenntnisse zusammengefasst werden.
1. Trump verfolgt auf Twitter eine klare (Kommunikations-)Strategie. Dies lässt sich u.a. durch die zeitliche Abhängigkeit verschiedener Aspekte beschreiben - beispielsweise der verwendeten Endgeräte/Applikationen für die Veröffentlichung von Tweets sowie der divergierenden Inhalte der Tweets. Generell lässt sich ab 2016 ein deutlicher Anstieg der Tweets beobachten. Wichtige Ereignisse innerhalb der betrachteten Zeitspanne haben vermutlich einen Einfluss auf die Inhalte und den Stil der Tweet, und könnten als Gegenstand späterer Untersuchungen dienen. [Clarke/Grieve 2019]
2. Die Medienkritik Trumps (auf Twitter) ist stark politisch geprägt und wird als Instrument für den Wahlkampf eingesetzt. Aus den Tweets extrahierte Hashtags und Begriffe beinhalten neben kritischen, häufig attackierenden Äußerungen gegen Medien und Nachrichten z.B. den Wahlslogan #makeamericagreatagain / #maga und #trump2016, später #kag ("Keep America Great"). Eine Wiederholung entsprechender Phrasen wie "'fake news', 'failing' und 'enemy of the American People'"[frei übersetzt nach Meeks 2019, S. 5] sorgt zudem für ein Framing bestimmter Medien bzw. des gesamten Mediensystems, welches auf besonders große Resonanz trifft.
3. Das hybride Mediensystem wurde von Trump für eine möglichst breite mediale Abdeckung ausgenutzt. Das Teilen von Informationen in sozialen Medien wie Twitter sorgt einerseits dafür, dass User ihre Zustimmung zu einer bestimmten Information bzw. Meinung geben können, andererseits werden hierdurch auch Informationen in ideologisch orientierten Communities, aber auch darüber hinaus weitergetragen - was schließlich wiederum die Aufmerksamkeit traditioneller Nachrichtenmedien erregen kann. [Wells et al. 2020, S. 664f.]
"Furthermore, Trump tweeted more at times when he had recently garnered less of a relative advantage in news attention, suggesting he strategically used Twitter to trigger coverage."
Wells et al. 2020, S. 559
Demnach greift Trump mit seinen Tweets nicht nur die Opposition an, sondern attackiert ebenso für ihn gefährliche Medien [Clarke/Grieve 2019, S. 20] [Wang et al. 2016, S. 719][Wells et al. 2020, S. 661], indem er mittels Framing ein bereits bestehendes Missvertrauen der Bevölkerung gegenüber den Medien verstärkt [Meeks 2019, S. 5]. Letztlich könnte sich das von Trump geschaffene und über Twitter weiter verbreitete Bild der Medien auch auf die generelle öffentliche Wahrnehmung der medialen Welt auswirken [Meeks 2019, S. 19]. ↑
Literaturangaben
Bortz, Jürgen (2005): Statistik für Human- und Sozialwissenschaftler, 6. Aufl., Berlin/Heidelberg: Springer.
Clarke, Isobelle & Grieve, Jack (2019): Stylistic variation on the Donald Trump Twitter account: A linguistic analysis of tweets posted between 2009 and 2018, in: PLoS One 14(9), S. 1-27. https://doi.org/10.1371/journal.pone.0222062
Downey, Allen B. (2014): Think Stats. Exploratory Data Analysis, 2. Aufl., O'Reilly Media, Inc.
Entman, Robert M. (1993): Framing: Toward clarification of a fractured paradigm, in Journal of Communication 43(4), S. 51-58. https://doi.org/10.1111/j.1460-2466.1993.tb01304.x
Meeks, Lindsey (2019): Defining the Enemy: How Donald Trump Frames the News Media, in Journalism & Mass Communication Quarterly 97(1), S. 211-234. https://doi.org/10.1177/1077699019857676
Wang, Yu; Luo, Jiebo; Niemi, Richard; Li, Yuncheng & Hu, Tianran (2016): Catching Fire via "Likes": Inferring Topic Preferences of Trump Followers on Twitter, in Proceedings of the Tenth International AAAI Conference on Web and Social Media (ICWSM 2016), S. 719-722.
Wells, Chris; Shav, Dhavan; Lukito, Josephine; Pelled, Ayellet; Pevehouse, Jon CW & Yang, Jung Hwan (2020): Trump, Twitter, and news media responsiveness: A media system approach, in new media & society 22(4), S. 659-682. https://doi.org/10.1177/1461444819893987